In this section, we’ll cover the steps of what a common pipeline includes for building software when using a CI/CD service. When you reach the end of this section, you’ll understand every step of the process in a common pipeline so that you can produce quality software.
A CI pipeline is a collection of steps required to code, build, test, and deploy software. Each step is not owned by a particular person but by a team working together and focusing on the goal to produce exceptional software. The good news is that if you followed the previous chapter’s recommendations, you’re already ahead of the game.
Each company’s pipeline can vary from product to product, but there will always be a common set of steps for a CI process. It depends on how detailed your pipeline becomes based on your needs. The stages in the pipelines can be influenced by each stakeholder involved in the process. Of course, pulling code and building and testing are required for the developers, but a QA team requires the finished product (artifact) to be sent to another server for test purposes.
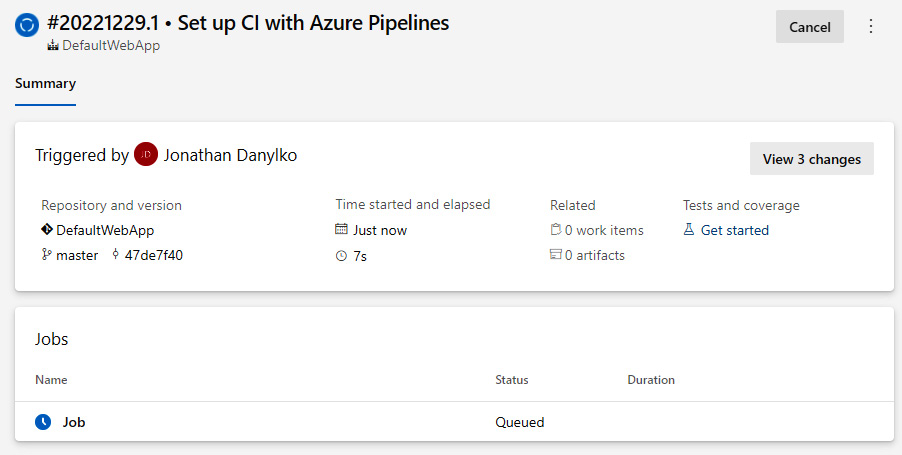
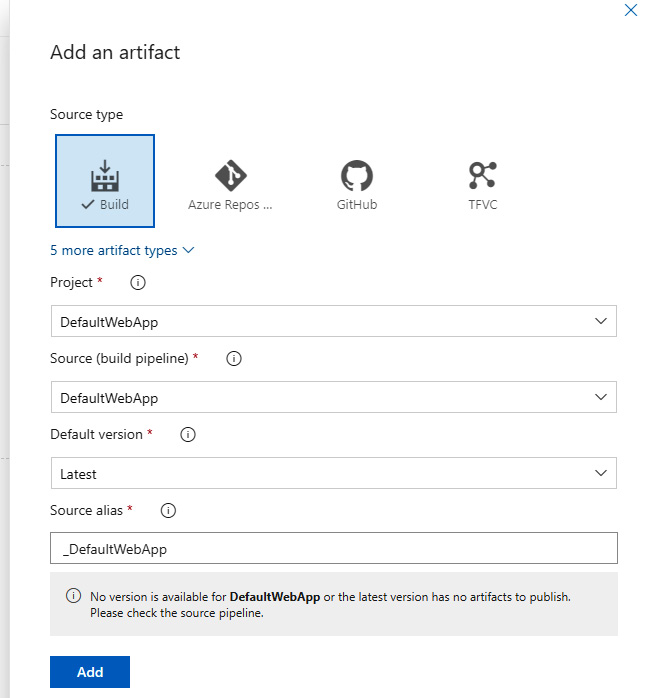
Figure 2.1 shows one common pipeline:
Figure 2.1 – One example of a build pipeline
As shown in Figure 2.1, the process is sequential when creating a software deployment. Here’s a summary of the steps:
- Pull code from a single repository.
- Build the application.
- Run unit tests/code analysis against the code that was built in step 2.
- Create the artifacts.
- Create a container (optional).
- Deploy the artifact(s) to a server (development/QA/staging/production).
Now that we’ve defined a common pipeline, let’s dig deeper into each step to learn what each process includes when you’re building your software.
In the following subsections, we’ll examine each process in detail based on the steps defined here.
Pulling Code
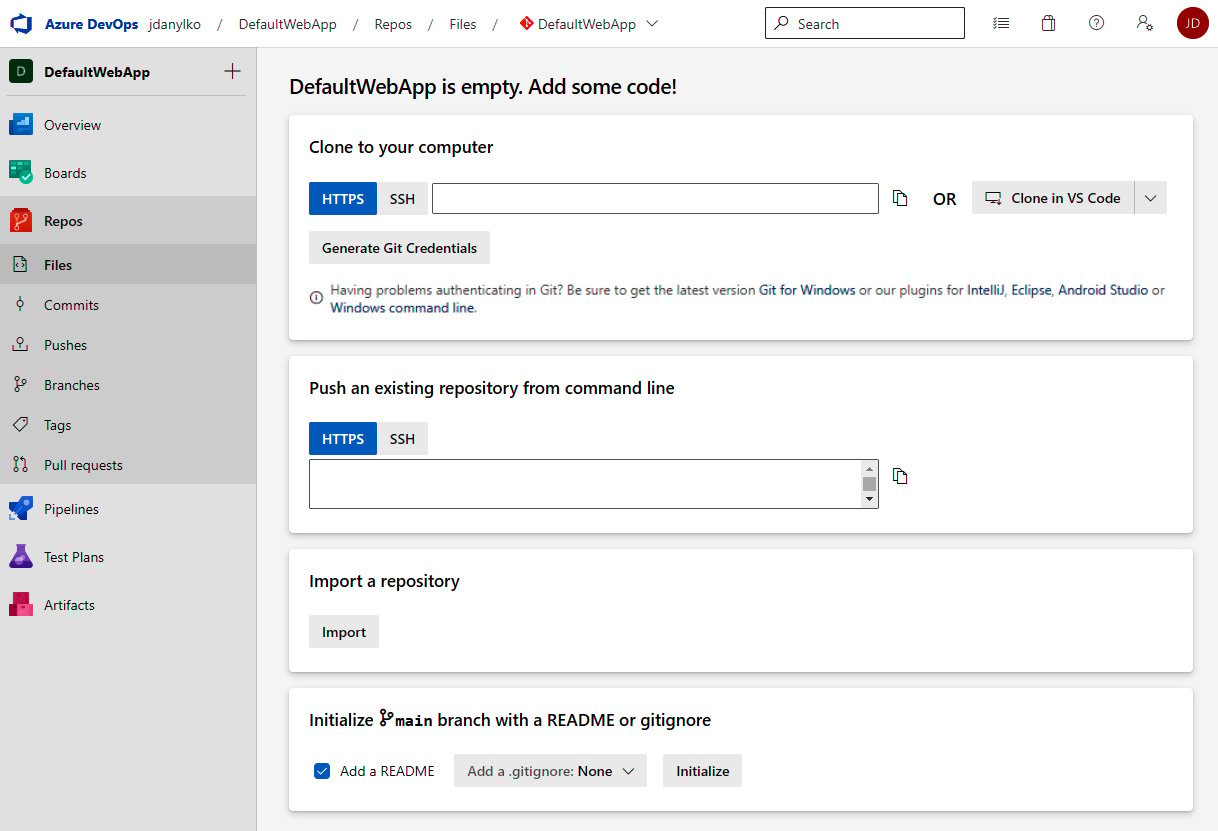
Before we build the application, we need to identify the project we’re building in our pipeline. The pipeline service requires a repository location. Once you’ve provided the repository URL, the service can prepare the repository for compilation on their server.
In the previous section, we mentioned why your code needs to compile flawlessly after cloning. The code is cloned and built on a completely different machine from yours. If the application only works on your computer and no one else’s, as the saying goes, “We’ll have to ship your computer to all of our users.” While this is a humorous saying in the industry, it’s generally frowned upon when writing and deploying software in the real world.
Each of the DevOps services has its benefits. For example, Azure Pipelines can examine your repository and make assumptions based on the structure of your project.
After analyzing the project, it uses a file format called YAML (pronounced Ya-mel) to define how the project should be built. While YAML is now considered a standard in the industry, we won’t deep-dive into everything YAML encompasses. YAML functionality could be a book on its own.
Azure takes your project’s assumptions and creates a YAML template on how it should build your application.
It knows how to compile the application, identify whether a container is included in the project, and also retrieve NuGet packages before performing the build.
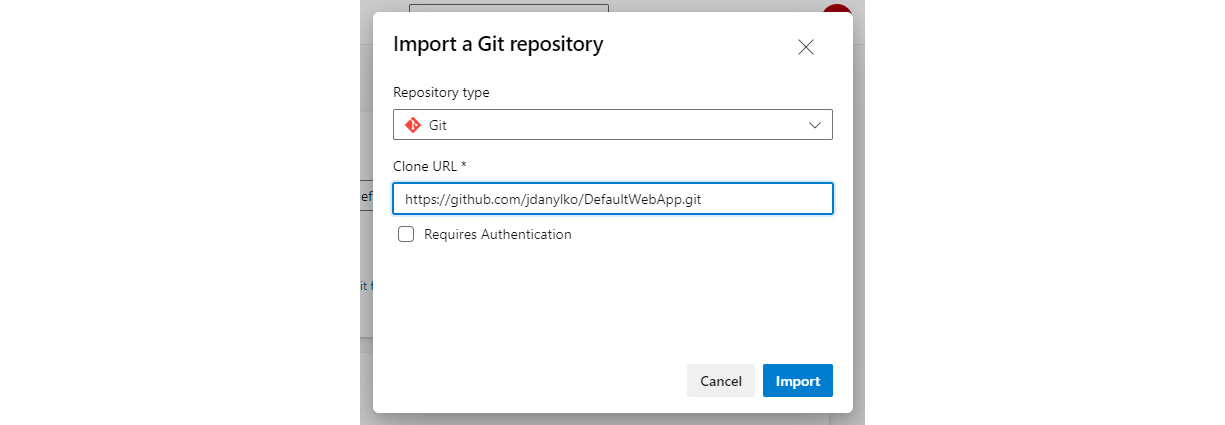
One last thing to mention is that most DevOp services allow one repository per project. The benefits of this approach include the following:
- Simplicity: It’s simpler to manage and build one application as opposed to orchestrating hundreds of applications in a project.
- Collaboration: Instead of multiple teams focusing on one large project, it’s easier to have one or two smaller teams working on a single, more manageable project.
- Faster builds: CI/CD pipelines are meant to provide fast feedback and even faster improvement. The smaller the project, the faster a build, test, and deployment will occur.
With that said, we are now ready to build the application.
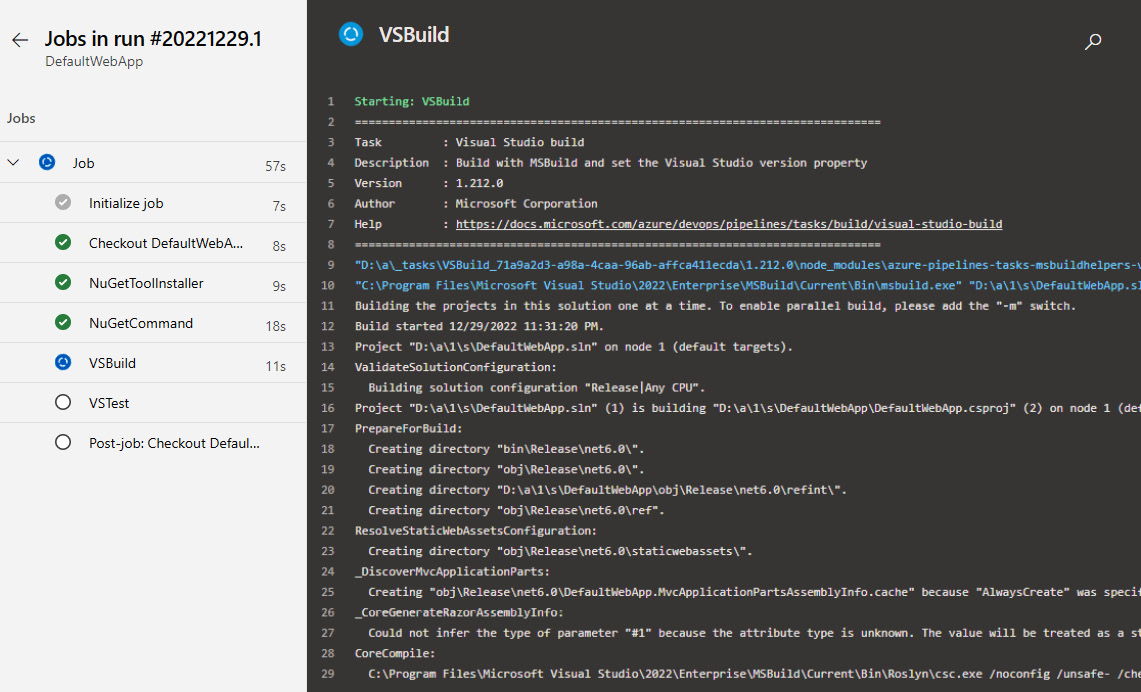
Building the application
As mentioned previously, YAML files define how the service proceeds with building your application.
It’s always a good practice to confirm the YAML file contains everything you need before building. If you have a simple project, the boilerplate included in the wizard may be all you need, but it allows you to make updates in case additional files are required, or other application checks.
It may take a couple of attempts to massage the YAML file, but once you get the file in a stable state, it’s great to see everything work as expected.
Make sure you have retrieved all your code before building the application. If this step fails, the process kicks out of the pipeline.
If you checked in bad code and the build fails, the proper authorities (developers or administrators) will be notified based on the alert level and you’ll be given the dunce hat or the stuffed monkey for breaking the build until someone else breaks it.
Next, we’ll focus on running unit tests and other tests against the application.
Running Unit Tests/Code Analysis
Once the build is done, we can move forward with the unit tests and/or code analysis.
Unit tests should run against the compiled application. This includes unit tests and integration tests, but as we mentioned previously, be wary of integration tests. The pipeline services may not have access to certain resources, causing your tests to fail.
Unit tests, by nature, should be extremely fast. Why? Because you don’t want to wait for 30 minutes for unit tests to run (which is painful). If you have unit tests taking that long, identify the longest-running unit tests and refactor them.
Once the code has been compiled and loaded, unit tests should be running every 10-30 seconds as a general guideline since they are memory-based.
While unit and integration tests are common in most testing scenarios, there are additional checks you can add to your pipeline, which include identifying security issues and code metrics to generate reports at the end of your build.
Next, our build creates artifacts to be used for deployments.
Creating Artifacts
Once the build succeeds and all of the tests pass, the next step is to create an artifact of our build and store it in a central location.
As a general rule, it’s best to only create your binaries once. Once they’ve been built, they’re available at a moment’s notice. These artifacts can deploy a version to a server on a whim without going through the entire build process again.
The artifacts should be tamper-proof and never be modified by anyone. If there is an issue with the artifact, the pipeline should start from the beginning and create a new artifact.
Let’s move on to containers.
Creating a Container
Once you have created the self-contained artifact, an optional step is to build a container around it or install the artifact in the container. While most enterprises use various platforms and environments, such as Linux or Windows, “containerizing” an application with a tool such as Docker allows it to run on any platform while isolating the application.
With containers considered a standard in the industry, it makes sense to create a container so that it can easily be deployed to any platform, such as Azure, Amazon Web Services (AWS), or Google Cloud Provider. Again, this is an optional step, but it’s becoming an inevitable one in the industry.
When creating a new project with Visual Studio, you automatically get a container wrapper through a generated Docker file. This Dockerfile defines how the container will allow access to your application.
Once you’ve added the Dockerfile to your project, Azure identifies this as a container project and creates the container with the included project.
Lastly, we’ll examine deploying the software.
Deploying the software
Once everything has been generated, all we need to do is deploy the software.
Remember the environment settings in your appsettings.json file? This is where they come in handy for deployments.
Based on your environment, you can assign a task to merge the appropriate environment JSON file into the appsettings.json file on deployment.
Once you have your environment settings in order, you can define the destinations of your deployments any way you like.
Deployments can range from FTP-ing or WebDeploy-ing the artifact or pushing the container to a server somewhere. All of these options are available out of the box.
However, you must deploy the same way to every environment. The only thing that changes is the appsettings file.
After a successful (or unsuccessful) deployment, a report or notification should be sent to everyone involved in the deployment’s outcome.
In this section, we learned what a common pipeline includes and how each step relies on a successful previous step. If one step fails throughout the pipeline, the process immediately stops. This “conveyor belt” approach to software development provides repeatable steps, quality-driven software, and deployable software.
 Argentina
Argentina
 Australia
Australia
 Austria
Austria
 Belgium
Belgium
 Brazil
Brazil
 Bulgaria
Bulgaria
 Canada
Canada
 Chile
Chile
 Colombia
Colombia
 Cyprus
Cyprus
 Czechia
Czechia
 Denmark
Denmark
 Ecuador
Ecuador
 Egypt
Egypt
 Estonia
Estonia
 Finland
Finland
 France
France
 Germany
Germany
 Great Britain
Great Britain
 Greece
Greece
 Hungary
Hungary
 India
India
 Indonesia
Indonesia
 Ireland
Ireland
 Italy
Italy
 Japan
Japan
 Latvia
Latvia
 Lithuania
Lithuania
 Luxembourg
Luxembourg
 Malaysia
Malaysia
 Malta
Malta
 Mexico
Mexico
 Netherlands
Netherlands
 New Zealand
New Zealand
 Norway
Norway
 Philippines
Philippines
 Poland
Poland
 Portugal
Portugal
 Romania
Romania
 Russia
Russia
 Singapore
Singapore
 Slovakia
Slovakia
 Slovenia
Slovenia
 South Africa
South Africa
 South Korea
South Korea
 Spain
Spain
 Sweden
Sweden
 Switzerland
Switzerland
 Taiwan
Taiwan
 Thailand
Thailand
 Turkey
Turkey
 Ukraine
Ukraine
 United States
United States